It's 255:19AM. Do you know what your validation criteria are?
A basic property of a digital signature scheme is that it should specify which signatures are valid and which signatures are invalid, so that all implementations can accept only valid signatures and reject only invalid signatures. Unfortunately, Ed25519 signatures don’t provide this property, making their use in distributed systems fragile and risky.
Although the scheme was standardized in RFC8032, the RFC does not specify validation criteria, and does not require conformant implementations to agree on whether a particular signature is valid. In addition, because the specification changed validation criteria years after deployment, it is incompatible with almost all existing implementations. Worse still, some implementations added extra ad-hoc criteria, making them further incompatible.
The result is an extremely wide variation in validation criteria across
implemententations. The diagram below plots verification results of a \(14
\times 14\) grid of edge cases, with light squares representing accepted
signatures, and dark squares representing rejected ones. As the diagram
illustrates, verification results are generally inconsistent not just between
implementations, but also between different versions and different modes.
Some protocols may tolerate this variation, but it is unacceptable for any
protocol that requires participants to reach consensus on signature validity.
A malicious participant can submit signatures that are accepted by some
implementations but rejected by others, causing a network partitition or a
consensus fork. Having only a single implementation makes this problem less
obvious, but it doesn’t go away, since behavior can vary across versions of the
‘same’ implementation. This occurred in practice with the widely used
libsodium library, which made breaking changes to validation criteria in a
point release.
Finally, although all of these problems occur when verifying signatures individually, they also prevent the use of batch verification, which can provide a significant performance benefit.
This post describes:
-
The structure of Ed25519 signatures and the scope of potential divergence in validation criteria (jump);
-
The results of a survey of Ed25519 validation behavior (jump), which revealed:
-
that almost no implementations conform to RFC8032;
-
that there is a wide variation in behavior not just between implementations, but also across different versions of the same implementation;
-
a platform-specific bug in Go’s
crypto/ed25519that gave different validation results on the IBM z/Architecture; -
a crash denial-of-service bug in Tor triggered by validating attacker-controlled signatures (though this bug was coincidentally not exploitable because of the way the function is currently used).
-
-
The ZIP215 rules (jump), a set of precisely defined validation criteria for consensus-critical Ed25519 signatures which resolve this problem. These rules are implemented in
ed25519-zebrain Rust and anded25519consensusin Go, are backwards-compatible with existing signatures, and will be deployed in Zcash as part of the Canopy network upgrade.
The scope of potential divergence
The Ed25519 signing process
Before explaining the validation criteria, it’s useful to briefly review the signing process. An honest signer generates their signing key, a random scalar \(a\), through a complicated procedure not relevant here. Then, they multiply their signing key by the Curve25519 basepoint \(B\) to obtain their verification key, a curve point \(A = [a]B\). The signing and verification keys are more commonly referred to as the private and public keys, but (following Daira Hopwood), I prefer to use the capability-based terminology, since it more precisely captures the role of the key material.
To sign a message M, a signer first generates a secret random nonce \(r\),
through a procedure that is also not relevant here, and then form a public
commitment to this randomness by computing \(R = [r]B\). Next, they use a
hash function \(H\) to compute a challenge scalar as \( k \gets H(R, A, M)
\). Finally, they compute a response scalar as \( s \gets r + ka \).
Divergence in Ed25519 signature validation criteria
To understand the scope of potential divergence in validation criteria, let’s
walk through the steps to verify a signature sig with verification key
\(A\) on the message M, noting each step with a possibly divergent behavior
choice. Then, in subsequent sections, we’ll look at the scope and implications
of each divergence.
Ed25519 signatures are 64 bytes long, structured as two 32-byte components:
sig = R_bytes || s_bytes. The first 32 bytes store an encoding of \(R\),
and the second 32 bytes store an encoding of \(s\). Ed25519 verification
keys are 32 bytes long, storing an encoding of \(A\).
Next, the verifier parses s_bytes as \(s\). It’s always possible to
interpret a byte string as a little-endian encoded integer, so parsing \(s\)
can’t fail. However, \(s\) is supposed to represent an integer \(\mod
q\), where \(q\) is the order of the prime-order subgroup of Curve25519.
Honestly-generated signatures will have \(0 \leq s < q\), and
implementations can choose to reject \(s \ge q\). Call this check
canonical \(s\).
Next, the verifier attempts to parse A_bytes as \(A\). Not all byte
strings are valid point encodings, so parsing \(A\) can fail, causing the
signature to be rejected. Points can be encoded non-canonically, although in
contrast to the encoding of \(s\), the mechanism is somewhat more complicated
and subtle, as will be described below. Implementations can
choose to reject non-canonically encoded curve points. Call this check
canonical \(A\).
The verifier then uses A_bytes, R_bytes, and the message M to recompute
the challenge value \(k \gets H(R, A, M)\). (Note that since \(H\) is a
hash function, it actually operates on the encodings A_bytes and R_bytes,
not their decoded internal representations).
Implementations then make a choice of verification equation, choosing which of two verification equations to check. They can use either the batched equation \[ [8]R = [8]([s]B - [k]A), \] or the unbatched equation \[ R = [s]B - [k]A. \] The naming of batched equation versus unbatched equation suggests that the difference is related to batched versus individual verification, but in fact these give different behavior even in the case of individual verification, as will be explained below.
Finally, to actually check whichever equation is used, an implementation must
choose an equality check. Recall that we didn’t actually decode R_bytes to
\(R\) yet. When using the batched equation, an implementation must operate
on \(R\), so it must decode R_bytes to \(R\), and check equality of curve
points. This also means it must make a choice of whether to require canonical
\(R\).
When using the unbatched equation, however, an implementation can choose to
either check equality of curve points, or to compute \(R’ \gets [s]B -
[k]A\), encode \(R’\) to Rprime_bytes, and check equality of byte strings.
When \(R\) is canonically encoded, these equality checks produce the same
result. But because the encoding procedure produces canonical encodings, if
R_bytes contains a non-canonical encoding of \(R\), then even if \(R’ =
R\) (as curve points), Rprime_bytes may differ from R_bytes (as byte
strings).
Points of potential divergence
In summary, there are a number of points of potential divergence between implementations:
- Whether to require canonical \(s\) or to allow non-canonical encodings.
- Whether to require canonical \(A\) or to allow non-canonical encodings.
- The choice of verification equation, either batched or unbatched.
- The choice of equality check, and the related choice of canonical \(R\).
- Any other ad-hoc checks added by a particular implementation.
Before comparing the choices made by RFC8032 and actually existing implementations, let’s examine the exact mechanism and implications of each of these points of potential divergence.
Canonical \(s\)
The values A_bytes, R_bytes, and M are all fed into the hash function, so
they cannot be modified without changing the challenge value. However, a third
party could replace \(s\) with \(s’ = s + nq\). Because \(s’ \equiv s
\pmod q\), the modified signature \((R, s’)\) would still pass
verification. Requiring that s_bytes encodes \(s < q\) prevents this.
This check is simple, low-cost, prevents malleability, is required by RFC8032, and is performed by most implementations. The only notable exception is the original reference implementation of Ed25519, which chose to write a paragraph arguing that signature malleability is never a problem instead of performing the check.
Because this check is fairly common, well-known, and unobjectionable, I didn’t focus on it, and didn’t comprehensively test implementation behavior.
Canonical \(A\), \(R\)
While the mechanism for constructing non-canonically encoded scalar values is fairly simple, the mechanism for constructing non-canonically encoded point values is somewhat more complicated, as mentioned above. To explain it, we need to describe the “compressed Edwards \(y\)” encoding used by Ed25519.
Curve25519 is defined over the finite field of order \(p = 2^{255} - 19\), so the coördinates of curve points \((x,y)\) are integers \(\mod p\). The curve equation in (twisted) Edwards form is \[ - x^2 + y^2 = 1 + d x^2 y^2, \] where \(d\) is a curve parameter. This means that \[ x^2 = \frac { y^2 - 1} {d y^2 + 1}. \] If the fraction on the right-hand side is nonsquare, then there is no \(x\) so that the right-hand side equals \(x^2\), and the \(y\) value is not the \(y\)-coördinate of a curve point. If it is square, then there is a square root \(x\), and the value of \(y\) is sufficient to recover \(x\) up to a choice of sign.
Because \(p < 2^{255}\), the encodings of field elements fit in 255 bits. The compressed Edwards \(y\) format uses the first 255 bits to store the \(y\) coördinate, and the 256th bit to indicate the sign of the \(x\) coördinate. To decode this format, an implementation parses \(y\) and the sign bit, and attempts to recover \(x\). If the square root exists, it uses the sign bit to select the sign. Otherwise, decoding fails.
The encoding has two components, and so there are two potential ways to construct a non-canonical encoding. First, we could try to use a non-canonical encoding of \(y\). Second, we could select \(y\) so that both sign choices give the same \(x\) value.
In the first case, encoding a field element non-canonically requires encoding
\(y\) as \(y + p\). But because field elements are encoded in 255 bits and
\(p = 2^{255} - 19\), this is only possible for the 19 values \( y = 0
\ldots 18 \) that can be encoded as \(y + p < 2^{255} \). Not all of
these values are \(y\)-coördinates of points, but because there are only a
few candidates, we can check every combination of enc(y) || 0 and enc(y) || 1 to enumerate them.
In the second case, we need \(x = -x\). This forces \(x = 0\). The curve equation is \[ - x^2 + y^2 = 1 + d x^2 y^2, \] so this requires that \( y^2 = 1 \), giving \( y = 1 \) and \(y = -1\) as the two candidate \(y\) values.
- When \(y = -1\), \(y\) can only be canonically encoded, so the
potential encodings are:
enc(-1) || 0(canonical);enc(-1) || 1(non-canonical).
- When \(y = 1\), \(y\) can be encoded non-canonically, so the potential
encodings are:
enc(1) || 0(canonical);enc(1) || 1(non-canonical);enc(2^255 - 18) || 0(non-canonical, included above);enc(2^255 - 18) || 1(non-canonical, included above).
This provides a mechanism for constructing non-canonically encoded points,
which I implemented in the test suite for
ed25519-zebra. In total, there are 25 such points. Of
these, 6 are of small order and are useful for constructing signature edge
cases, as described in the next section. (This taxonomy was created with
pointers from Sean Bowe and NCC Group).
Choice of verification equation
Recall that implementations can use one of two verification equations, the batched equation \( [8]R = [8]([s]B - [k]A) \), or the unbatched equation \( R = ([s]B - [k]A) \). The only difference between these two equations is that the first one multiplies by \(8\). For honestly generated signatures, \(s = r + ka\), \(A = [a]B\) and \(R = [r]B\), so \[ \begin{aligned} [s]B - [k]A &= [r + ka]B - [k]A \\ &= [r]B + [k]([a]B) - [k]A \\ &= R + [k]A - [k]A \\ &= R \end{aligned} \] and both equations are satisfied. So, why are there two verification equations, and what is their relationship to batch verification?
To explain this, we need to know some facts about the structure of the Curve25519 group. Many abstract cryptographic protocols require an implementation of a group of large prime order \( q \). This is usually provided using an elliptic curve, such as Curve25519, where \(q \sim 2^{252}\). However, Curve25519 and other curves that can be written in Edwards form don’t have prime order. Instead, they provide a group of order \( hq \) for a small cofactor \(h\), such as \(h = 8\) in the case of Curve25519. More information on cofactors can be found on the Ristretto website.
This means that in addition to the prime-order subgroup, Curve25519 also contains a “torsion” subgroup of small-order points. The structure of the full Curve25519 group is \(\mathbb Z / q \mathbb Z \times \mathbb Z / 8 \mathbb Z \), meaning that every point \(P\) in the full group can be written uniquely as the sum \(Q + T\) of a point in the prime-order subgroup (call this the prime-order component) and a point in the torsion subgroup (call this the torsion component).
When we multiply \(P\) by \( 8 \), the prime-order component will be \([8]Q\). Since \(8\) and \(q\) are coprime, we could recover \(Q\) from \([8]Q\) by multiplying by \(1/8 \pmod q\), so this “shifts” the prime-order component around but doesn’t lose any structure. However, because every point in the torsion subgroup has order dividing \(8\), \([8]T = 0\), and the torsion component is killed by the multiplication-by-\(8\) map.
What does this mean for the two verification equations? Because multiplication by \(8\) kills the torsion component, the batched equation can be thought of as checking validity only in the prime-order subgroup, while the unbatched equation can be thought of as checking validity in the full group. Honest Ed25519 signers only work in the prime-order subgroup, so the two verification equations give the same results for honestly-generated signatures.
But nothing stops a signer from deviating from the protocol, and generating a verification key with nonzero torsion component. As one concrete example, they can choose a torsion point \(T\) of order \(8\), and publish \(A’ = [a]B + T\) as their verification key instead of \(A = [a]B\). If they sign messages as normal, they’ll choose a random \(r\), generate \( R \gets [r]B \) and \( s \gets r + ka \). Now, consider what happens to \([s]B - [k]A’\): \[ \begin{aligned} [s]B - [k]A’ &= [r + ka]B - [k](A + T) \\ &= [r]B + [k]A - [k]A - [k]T \\ &= R - [k]T. \end{aligned} \]
A verifier using the batched equation will accept the signature if \([8]R = [8]([s]B - [k]A’)\). Since \([s]B - [k]A’ = R - [k]T\) and \([8]T = 0\), \[ [8]([s]B - [k]A’) = [8]R - [8][k]T = [8]R \] and the batched equation is always satisfied.
However, a verifier using the unbatched equation will accept the signature only if \([k]T = 0\), which happens whenever \(8\) divides \(k\). Since \(k = H(R, A, M)\) is a uniformly distributed hash output, the signer has a \(1/8\) chance of generating a signature that passes unbatched verification.
Batch verification
We’ve now seen the difference between the verification equations. To understand the connection to batch verification, we need to describe how batch verification works.
Batch verification asks whether all items in some set are valid, rather than asking whether each of them is valid. This can increase throughput by allowing computation to be shared across items. In the case of Ed25519, batch verification works as follows. First, rearrange the verification equation as \[ 0 = [8]R - [8][s]B + [8][k]A, \] so that we’re checking whether the verification term on the right-hand side is zero.
In the batch setting, we have multiple (message, key, signature) pairs, and we want to check whether all of their verification terms are zero. To do this, we take a linear combination of the verification terms with coefficients \(z_i\): \[ 0 = \sum_i z_i \left( [8]R_i - [8][s_i]B + [8][k_i]A_i \right). \] This equation will hold for all values of \(z_i\) if and only if all of the verification terms are zero. This would be computationally infeasible to check directly, but the verifier can instead select random, high-entropy values for \(z_i\). Because we’re working in a prime-order (sub)group, if any verification terms are nonzero, they’ll remain nonzero after multiplication by \(z_i\).
Why is this preferable? The reason is that it allows the verifier to compute a single multiscalar multiplication of multiple points and scalars. This can be performed much more efficiently than computing multiple individual scalar multiplications and summing the results.
In practice, the verifier uses a slightly rewritten equation,
\[
0 = [8]
\left(
\left[ - \textstyle\sum_i z_i s_i \right] B
+ \sum_i [z_i] R_i
+ \sum_i [z_i k_i] A
\right).
\]
This coalesces the coefficients of the basepoint into a single term, reducing
the size of the multiscalar multiplication, and does a single cofactor
multiplication (three doublings) at the end. This can easily provide a 2x or
more speedup on verification. It’s possible to go further:
ed25519-zebra implements an adaptive strategy that detects
reused verification keys, giving an extra 2x speedup in
the limiting case where all signatures are made with the same verification key.
However, if we tried to do this without multiplication by the cofactor (as in the original Ed25519 paper), we’d get totally inconsistent behavior in the presence of one or more candidate signatures with nonzero torsion components.
First, verification results would become probabilistic, because the random coefficients might or might not kill the torsion components. Second, verification results might depend on which items are or aren’t included in the batch, if small-order components from one term cancel with small-order components from another. Third, and most surprisingly, it’s possible to construct signatures that pass single verification but fail (cofactorless) batch verification, even in a single-element batch!
Why is this last case surprising? If a signature satisfies the unbatched equation \(R = [s]B - [k]A\), the verification term \( R - [s]B - [k]A \) is zero. But (cofactorless) batch verification computes a random linear combination of this term, and the term is zero, so how could the combination be nonzero?
The answer lies in a subtle implementation detail. What the verifier actually checks is not \[ 0 = z \left( R - [s]B + [k]A \right) \] but \[ 0 = [-zs]B + [z]R + [zk]A. \] Suppose that, e.g., \(A\) had a torsion component of order \(8\), and that \(8\) divides \(k\). Then in the first case, the verifier computes \([k]A\) and multiplication by \(k\) kills the torsion component of \(A\). In the second case, the verifier computes \([zk]A\). Since \(8\) divides \(k\), we might expect that \(8\) divides \(zk\). But every existing implementation implements scalar arithmetic \(\mod q\), the order of the prime-order group, not \(\mod 8q\), the order of the full group. So the verifier first computes \(zk \mod q\), and then uses the resulting integer representative, which might not be divisible by \(8\), to perform scalar multiplication.
The root cause of this problem is that the scalar arithmetic in Ed25519 implementations only produces well-defined results on the prime-order subgroup, not the full group. This is bad because it means that basic laws of arithmetic (e.g., that rearranging terms shouldn’t change the value of an expression) don’t apply unless we restrict to the prime-order subgroup.
For these reasons, the only way to make batch verification produce internally consistent results is to use the batched verification equation that includes multiplication by the cofactor.
A survey of implementation behaviors
Ed25519 is widely implemented and used in various consensus-critical contexts. As we’ve seen above, there are in principle several points of potential divergence between implementations. Do these occur in practice? To find out, I collected a list of systems to look at, and checked their behavior against the test vectors I created for ZIP215, a set of validation rules described below which fix this problem in Zcash.
Constructing test vectors
Because the potential divergence happens on edge cases, not on honestly-generated signatures, if we want to check for divergent behavior, we need to construct specially crafted test vectors that will produce different behavior when implementations make different choices.
How could we do this? Let’s start by examining the unbatched equation \[ R = [s]B - [k]A. \] When we’re constructing test cases, we have direct control over \(R\), \(s\), and \(A\). Since \(k\) is a hash output, we can’t control its value, but it will vary depending on our choices. We have no control over \(B\), which is a system parameter.
Now, we know from the preceding discussion that one big source of divergent behavior is the presence of torsion components. So, we could set \(A\) and \(R\) to be small-order points. Because the torsion subgroup is so small, there’s a reasonable chance of cancellation between the \(R\) and \([k]A\) term. The remaining term is the \([s]B\) term, which we can eliminate by setting \(s = 0\). The resulting signature will sometimes satisfy the unbatched equation, depending on whether \(k = H(R,A,M)\) causes \(R = -[k]A\), and will always satisfy the batched equation, because small-order terms are killed by cofactor multiplication.
If we choose non-canonical encodings of small-order points, then in addition to testing the choice of verification equation, we can also test the choice to require canonical encodings of \(A\) or \(R\), and the choice of equality check. There are 8 small-order points, each with a canonical encoding. There are also 6 non-canonical encodings of small-order points. Together, this gives \(14 \times 14 = 196\) test cases.
Survey results
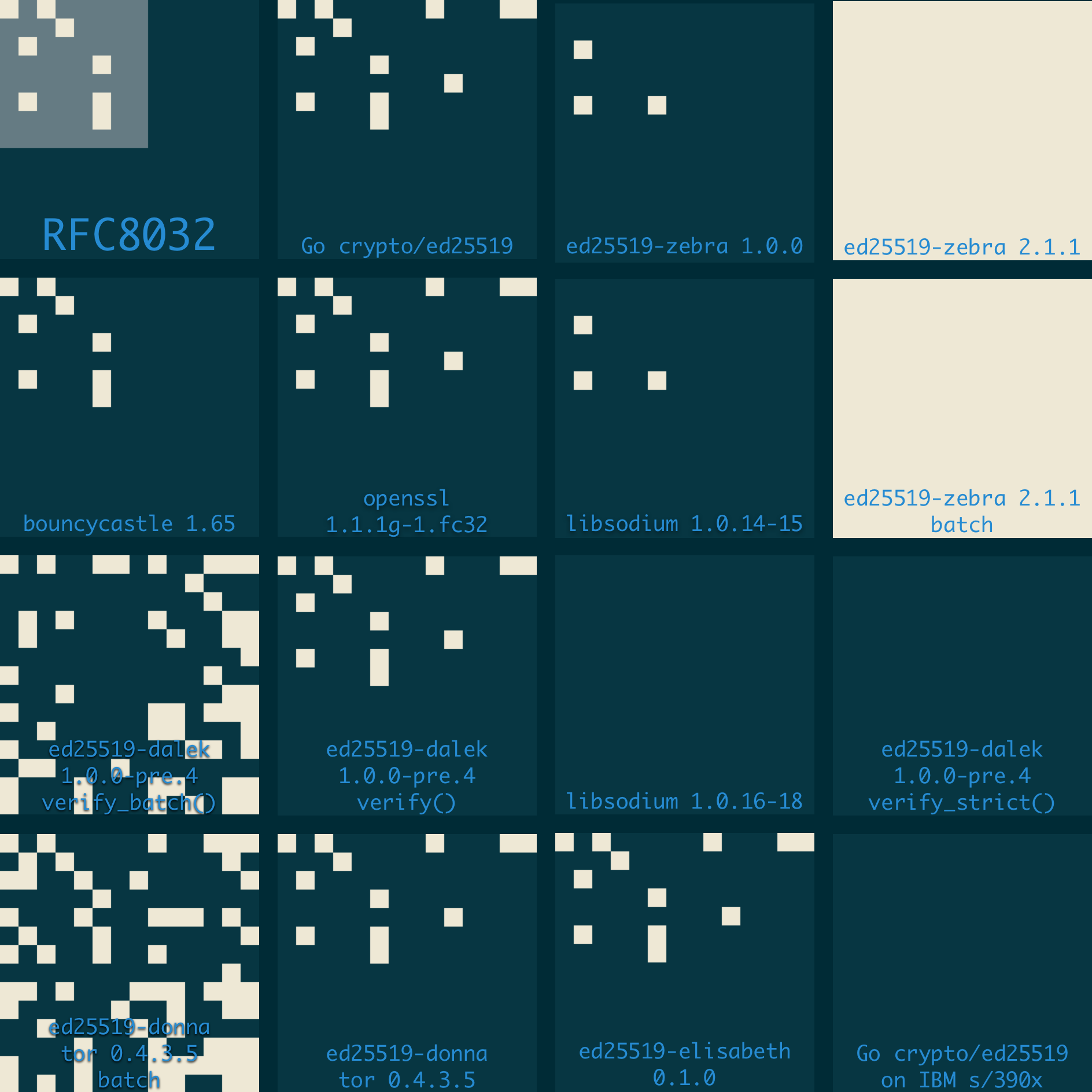
The image at the top of the post and repeated here shows the results of
verifying the 196 test cases as signatures on the message b"Zcash".
Each pixel corresponds to a verification result. Light pixels represent
accepted signatures, and dark pixels represent rejected ones. In the case of
RFC8032, the medium shade represents signatures which implementations MAY
accept, if they are so inclined. Each row corresponds to a choice of
R_bytes, and each column corresponds to a choice of A_bytes.
This visualization shows multiple different, mutually incompatible “families” of verification behavior. (Click the image to open full-size).
RFC8032
First, we can see that RFC8032 is incompatible with every implementation tested, with the exception of Bouncycastle. The RFC, which was written several years after wide deployment, added a requirement that implementations MUST reject non-canonical encodings. But no then-existing code implemented this requirement.
However, because the RFC allows either the batched or unbatched verification, even if there were two implementations conforming to the RFC, there would still be no guarantee of compatible behavior.
”Classic” criteria
A second family of common behavior includes implementations matching the
behavior of the ref10 reference implementation, usually because they are
derived from it in some way. This includes Go’s crypto/ed25519, OpenSSL,
ed25519-donna (as used in Tor), ed25519-dalek’s verify, and
ed25519-elisabeth.
These implementations use the unbatched verification equation, and do not check
that \(A\) is canonically encoded. However, because they recompute \(R’\),
encode it to Rprime_bytes, and check that R_bytes = Rprime_bytes, they do
check that \(R\) is canonically encoded, but only by accident. The
visualization reflects this in the fact that there are no valid signatures in
the lower 6 rows corresponding to non-canonical encodings of \(R\).
libsodium
Another family of common behavior includes libsodium and implementations
attempting to be compatible with it. When used without the ED25519_COMPAT
build flag, libsodium uses an additional ad-hoc validation step, checking
against a hard-coded list of excluded point encodings. This additional
validation step introduces incompatibility, but it doesn’t solve the problems
related to torsion components, since it only excludes small-order points
\(T\) and not points with a small-order component \(Q + T\).
However, the validation behavior changed in a point release
from 1.0.15 to 1.0.16. In 1.0.15, R_bytes is checked against the list
of excluded point encodings, while A_bytes is checked to be nonzero. This
change was a problem for Zcash, because the initial implementation of Zcash
consensus in zcashd inherited Ed25519 validation criteria from the version of
libsodium it used. As a result, zcashd was stuck using an old version of
libsodium, because upgrading would be a breaking change to the consensus rules.
Two implementations attempt to match libsodium behavior. ed25519-zebra’s
1.x series provides exact bug-for-bug compatibility with libsodium 1.0.15
as used in zcashd. ed25519-dalek’s verify_strict method matches the
libsodium 1.0.16-18 behavior.
Go on IBM s/390x
The IBM z/Architecture contains many interesting instructions, one of
which is the KDSA “compute digital signature authentication”, which provides
access to hardware implementations of signing and verification for Ed25519,
Ed448, and ECDSA over the NIST P256, P384, and P521 curves.
Go’s crypto/ed25519 contained a platform-specific backend that called this
hardware implementation when available. However, running these test vectors
revealed an incompatibility between the software implementation and
the hardware implementation.
Batch verification
Three of the tested implementations perform batch verification:
ed25519-zebra, ed25519-dalek, and ed25519-donna. Each test case was
verified in a batch of size 1.
None of these implementations require \(R\) or \(A\) to be canonically
encoded. In the case of ed25519-dalek and ed25519-donna, this behavior
differs from the single verification mode, which accidentally requires \(R\)
to be canonically encoded.
ed25519-zebra uses the batched verification equation, so all test cases
verify. ed25519-dalek and ed25519-donna use the unbatched equation for
batch verification, so verification depends on the values of the z_i. This
produces incompatible results from each other and from their implementation of
single verification.
The incompatibility between ed25519-donna’s batch verification and its single
verification created a denial-of-service bug in Tor which allows an
adversary who can control the input to batch verification to crash the Tor
process. This happens because the batch verification implementation falls back
to single verification in case of a batch failure and performs a defensive
consistency check. However, passing signatures that verify individually but
not as part of a batch causes the consistency check to fail and trigger an
assertion. Luckily, this is not exploitable, because batch verification is
only used for batches of size greater than 3, but no caller supplies such a
batch, and so the batch verification codepath is never used.
Fixing the problem
Ed25519 signatures are widely used in consensus-critical contexts (e.g., blockchains), where different nodes must agree on whether or not a given signature is valid. In these contexts, incompatible validation criteria create the risk of consensus divergence, such as a chain fork.
Mitigating this risk can require an enormous amount of effort. For instance,
the initial implementation of Zcash consensus in zcashd inherited
validation criteria from the then-current version of libsodium 1.0.15.
Due to a bug in libsodium, the actual behavior was
different from the intended criteria, which had been documented in the Zcash
protocol specification, so the specification had to be corrected to match.
Because libsodium never guaranteed stable validation criteria, and changed
behavior in a later point release, zcashd was forced to use an older version
before eventually patching a newer version. This meant that Zebra, the Zcash
Foundation’s Zcash implementation had to implement
ed25519-zebra, a library attempting to match libsodium
1.0.15 exactly. And the initial implementation of ed25519-zebra was also
incompatible, because it precisely matched the wrong compile-time configuration
of libsodium.
Instead of attempting to replicate implementation-defined behavior, a better solution would be to select a precise set of validation criteria. There are two basic choices which determine the resulting validation criteria.
Selecting precise criteria
Should the validation criteria allow batch verification, or not? In order to allow batch verification, batch and single verification must always agree, which means that single verification must use the batch equation, rather than the unbatched equation.
The only downside of using the batch equation for single verification is that it requires an additional 3 doublings to compute the multiplication by \(8\). This costs a bit more than 1000 Skylake cycles, or about 1-2% of the total cost of a single verification. The upside is that batch verification can provide a speedup of 2x or more.
Should the validation criteria be backwards-compatible, or not? Most existing implementations don’t require canonically-encoded points. If every signature that was considered valid by an existing implementation is considered valid under the new rules, an implementation of the new rules can be used in place of an existing implementation. On the other hand, if the new rules are more strict than the previous ones, it might be possible for someone to insert a signature valid under the old rules and not the new ones, which could cause unexpected breakage.
There’s no downside and no security impact to allowing non-canonical point encodings, because this choice only affects signatures created with specially crafted verification keys. Honest participants generate their signing and verification keys according to the protocol, and are unaffected either way.
The ZIP215 rules
To fix this problem in Zcash, we chose to support both batch verification and
backwards compatibility. The resulting rules are specified in ZIP215,
scheduled to activate as part of the Zcash Canopy network upgrade,
implemented in Rust in ed25519-zebra’s 2.x series, and
implemented in Go in a new ed25519consensus library.
Although this work was motivated by the problem in Zcash, the same risk exists
in other projects. For instance, Tendermint uses Go’s crypto/ed25519, which
means that any future consensus implementations, such as
tendermint-rs need to carefully consider and mitigate the
risk of consensus incompatibilities, and interoperability mechanisms like IBC
that are likely to have multiple implementations need to specify precise
validation criteria. In either case, upgrading to the ZIP215 rules may be
helpful.
Thanks to Sean Bowe, Daira Hopwood, and Deirdre Connolly for their comments on
the ZIP215 draft and for pointers on non-canonical point encodings, to Saleem
Rashid for comments on the summary, to teor for pointers on Ed25519 use in Tor,
to Mike Munday for running the crypto/ed25519 tests on IBM z/Architecture, to
Patrick Steuer for creating C-encoded versions of the test vectors and testing
them on OpenSSL, and to Filippo Valsorda for assistance creating the
ed25519consensus library.